一、引言
众所周知,CovScript 并不支持多线程(Multi-thread)编程。这是因为受限于当前主流运行时环境——即 CovScript 3 解释器的底层架构,使其难以在现有机制下高效地兼容多线程并发模型。
不过,CovScript 在语言层面并没有停滞不前。自 STD210506(v3.4.2) 起,CovScript 就引入了 协程(Coroutine,或 Fiber) 概念,并在 STD251001(v3.4.4) 中进一步完善,增加了嵌套协程等特性。这一演进让 CovScript 能够以极小的开销实现轻量级的异步并发模型,足以满足大多数 I/O 密集型应用的需求。
下图展示的是一个基于 NetUtils 包搭建的 HTTP 服务器,在龙芯 3A4000 上运行的性能测试结果(使用 wrk 模拟一万并发请求):
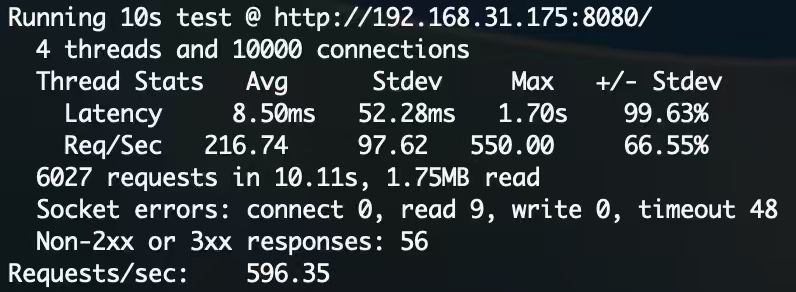
可以看到,即使在性能水平接近树莓派的 CPU 上,CovScript 依然能够稳定支撑高并发请求。从某种意义上说,这一结果不仅验证了 CovScript 协程机制的成熟度,也进一步说明了协程模型在资源受限环境下的优越性——在不依赖多线程调度的前提下,同样能实现高效并发。
二、现代并发模型
2.1 传统并发模型
在谈并发模型之前,先要回答一个更基础的问题:
我们为什么需要并发?
计算机执行的任务大致可以分为两类:计算密集型(Computing Intensive) 和 I/O 密集型(I/O Intensive)。计算密集型任务非常好理解,比如大模型的推理或训练,这类任务的性能主要取决于硬件算力,几乎无法通过编程模型直接提升性能。
相比之下,I/O 密集型任务更加常见。传统编程模型通常采用同步 I/O(阻塞 I/O)语义,也就是说,CPU 在发起 I/O 操作后必须等待其完成,期间几乎处于空转状态。举个例子,当我们在命令行中执行 curl 或 wget 命令时,当前 Shell 会等待数据从网络返回,这段时间里 CPU 并没有真正“工作”,瓶颈完全在网络通信上——而网络带宽相比内存带宽和 CPU 时钟速度要慢几个数量级。
那么,如何避免 CPU 的空转?答案就是并发。上世纪末到本世纪初,多线程编程(Multi-threading) 成为主流方案。几乎所有计算机相关专业的学生都在本科阶段学习过这一内容。
多线程是传统并发模型的核心,它比早期的多进程模型更轻量(创建与销毁的成本更低),并由操作系统负责调度。它既可以在单个 CPU 核心上通过时间片切换实现“宏观并发”,也可以在多核环境下实现真正的并行。例如,当我们有两个互不依赖的 I/O 任务时,早期模型只能串行执行,而多线程模型可以同时发起两个线程并等待结果,从而显著缩短整体执行时间。
然而,多线程并不是没有代价。主要有两方面问题:
(1)竞态条件(Race Condition):线程的调度完全由操作系统决定,执行顺序不可控,甚至可能在多个核上同时运行。因此我们必须使用同步机制来保护共享数据,如原子操作(Atomic)、互斥锁(Mutex)等。这些机制虽然能保证正确性,但性能开销不容忽视。以原子量为例,普通变量的读取可能只需 1~2 个 CPU Cycle,而原子量的读取往往要消耗十几个 Cycle。别小看这点差距——程序中变量访问可能达到数亿次,累计开销极为可观。此外,原子操作会引入内存屏障(Memory Barrier),降低缓存命中率,使性能进一步下滑。这些因素叠加在一起,使得多线程编程既复杂又难以调试。
(2)调度开销(Scheduling Overhead):在现代操作系统中,线程本质上是一种轻量级进程,其创建、切换与销毁的开销虽然比进程低,但依然是毫秒级开销。同时,线程数量受系统资源(如文件描述符或句柄上限)限制,无法无限扩张。即便通过线程池复用线程,也难以彻底消除调度与同步的成本。
综上,虽然多线程模型推动了并发编程的发展,但其复杂性和开销也促使人们不断寻找更高效的方案。进入 21 世纪后,以 Go 语言为代表的新兴编程语言,将非阻塞式 I/O 和协程(Coroutine)的理念带入主流,开启了并发编程的新篇章。
2.2 非阻塞式 I/O
随着多线程模型在各类系统中被广泛采用,人们逐渐意识到,它并非万能的并发解法。当线程数量持续增长时,调度、同步和上下文切换的成本开始迅速累积,最终让系统在高并发场景下反而变得低效。这时,另一种思路出现了——非阻塞式 I/O(Non-blocking I/O)。
它的核心思想很简单:不要等待。当某个 I/O 操作无法立即完成时,不让 CPU 空转,而是立即返回控制权,让程序先去处理其他任务,等 I/O 准备好后再回来继续。这种机制看似简单,却彻底改变了并发的执行方式。从操作系统的 select/poll 到后来的 epoll、kqueue,再到现代语言的事件循环模型(如 Node.js 的 Event Loop、Go 的 Netpoller),非阻塞式 I/O 逐渐成为高性能网络服务的基础。
以 Socket I/O 为例,我们来看看阻塞式与非阻塞式 I/O 的区别。
# 阻塞式 I/O
var sock = new tcp.socket
sock.connect(...)
# 阻塞当前线程等待套接字返回数据
var data = sock.read(1024)
# 处理数据
process_data(data)在这种模型下,程序会在 read 调用处停下来,直到数据到达为止。这种方式的最大优点是简单直观。代码的逻辑是线性的,编写与阅读都非常自然。因此,对于并发需求不高的场景,比如命令行工具、小型脚本、一次性网络请求等,阻塞式 I/O 依旧是首选。
# 非阻塞式 I/O
var sock = new tcp.socket
sock.connect(...)
# 提交一个非阻塞式 I/O 任务,函数会立即返回
var state = async.read(sock, 1024)
loop
# 轮询事件,函数会立即返回
async.poll()
# 这里可以随意做些其他事情
until state.has_finished()
# 处理数据
process_data(state.get_result())非阻塞式 I/O 的核心思想是:不要等待。当 I/O 操作尚未完成时,函数立即返回控制权,程序可以继续执行其他任务。后台的事件系统(通常基于 epoll、kqueue 等机制)会在 I/O 准备好后触发事件通知。这种机制背后的驱动力就是事件循环(Event Loop):程序在一个循环中持续监听事件,而 CPU 空闲的时间片则被充分利用。
多个非阻塞 I/O 操作可以同时进行。例如,我们可以在同一个套接字上同时发送和接收数据(套接字本身是全双工的):
# 同时提交两个任务
var rstate = async.read(sock, 1024),
wstate = async.write(sock, data)
loop
rsync.poll()
# 这里可以随意做些其他事情
until rstate.has_finished() && wstate.has_finished()
# 任务完成通过一个事件循环,程序就能同时管理多个 I/O 任务。无需为线程安全操心,也无需承担频繁上下文切换的代价。就算是刚入门编程的小白,到这里也应该能体会到非阻塞式 I/O 的好处了 :)没有竞态条件、没有锁、调度开销小,且充分利用 CPU。这正是现代高性能网络程序的基础所在。
2.3 协程(Coroutine)
非阻塞式 I/O 解决了“CPU 空转”的问题,但它带来了新的烦恼:代码不再直观。我们必须手动管理事件轮询、状态查询与回调逻辑,代码容易变得支离破碎。尤其在多个异步操作互相嵌套时,程序员要在心里维护一张复杂的状态机图,这就是大家常说的“回调地狱(Callback Hell)”。协程的出现正是为了解决这个问题。
协程的核心思想是:让异步代码写起来就像同步代码一样自然。
协程允许一个函数在执行过程中暂停(挂起),并在合适的时机恢复(唤醒),同时保留完整的上下文(局部变量、执行栈等)。这意味着,协程能让阻塞式 I/O 也变得“并发”,在等待 I/O 的过程中不会阻塞整个线程,而是把控制权交还给调度器;一旦数据准备好,协程会从上次暂停的地方继续执行,仿佛从未中断。
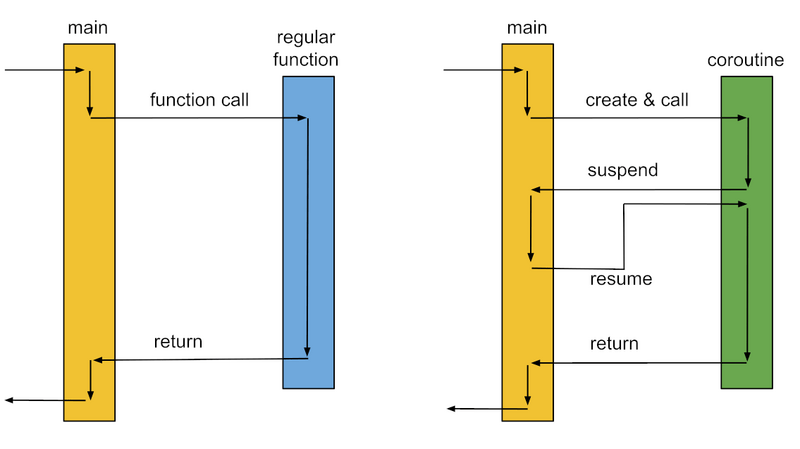
CovScript 基于协程提供了一种轻量级的异步基础设施,使我们能够以同步的编程方式,获得异步的执行效果。
function handle_connection(sock)
# 自动挂起(Yield)等待 I/O
var data = runtime.await(sock.read, 1024)
var response = process_data(data)
# 自动挂起(Yield)等待 I/O
runtime.await(sock.write, response)
end
# 阻塞式 I/O + 协程
var sock = new tcp.socket
sock.connect(...)
# 将普通函数转换为协程
var co = fiber.create(handle_connection, sock)
loop
# 手动切换至协程
co.resume()
# 这里可以随意做些其他事情
until co.is_finished()
# 任务完成在这段代码中,我们使用了 CovScript 的 runtime.await 来并行等待阻塞式 I/O 的完成。它的实现原理非常巧妙:await 在内部会启动一个线程执行目标函数,并在执行期间自动调用 fiber.yield()。正因如此,我们在协程体内看不到显式的 yield 调用。yield 的作用是将控制权返回给上层调用者(此处是主程序),而 resume 则是重新激活协程。二者相互配合,构成了协程最核心的执行循环。
换句话说,虽然底层依然是阻塞式 I/O,但我们通过协程调度机制,让这些阻塞操作“看起来”是并发执行的。整个系统并没有依赖操作系统的线程调度,而是通过语言级协作实现了轻量级的异步并发。
协程的开销远低于线程,甚至低于函数调用,其运行不依赖操作系统调度,它的切换由语言运行时控制。一个协程通常只需几 KB 栈空间,可以轻松同时运行成千上万个协程,而系统线程的开销则要大得多(通常在 MB 级别)。这让协程成为高并发场景下的理想选择:轻量、高效、无锁、可控。
为了让协程的轻量级优势更直观,我们来看几个实测数据。
在 Apple M2 平台上,CovScript 的顺序执行性能可以达到 每秒约 600 万行代码,这已经接近大多数动态语言在未开启 JIT 的情况下的极限了。令人惊讶的是,CovScript 的协程切换性能远超这个水平:
每秒可达近 400 亿次上下文切换!(没错,是 400 亿次)
也就是说,只要协程切换不是极端频繁,它的开销几乎可以忽略不计。相比传统的回调函数方式,协程不仅语义清晰、易维护,而且在性能上也更经济、高效。这一数据直观地说明了协程作为轻量级并发工具的潜力,即便在普通硬件上,也能支撑数以亿计的并发上下文切换,为高并发场景提供了坚实的基础。
作者补充:CovScript 协程的后台实现基于著名的 libucontext,并在此基础上进行了大量优化与适配。协程切换的底层操作其实非常轻量:只涉及少量寄存器的保存与恢复,且栈空间仅需 KB 级别的内存。这在缓存比较大的高性能 CPU 上甚至都不会导致 Cache Miss。相比之下,即使是普通的函数调用(无论是 C++ 还是 CovScript),也需要做大量额外工作:初始化保护机制(如栈保护、异常处理等)、对局部变量或上下文进行深拷贝等。因此,协程在效率上甚至可以超越未经内联的函数调用。这也解释了为什么 CovScript 即使在数百亿次上下文切换的场景下,开销依然微乎其微。协程不仅轻量,而且高效。
三、基于 CovScript 的异步编程
3.1 Code of Conduct
在讲干货之前,作者想先和读者们聊一聊设计 CovScript 以及其相关基础设施时所遵循的原则。
在现代编程语言中,如 Go、Python 等,异步编程已经成为语言层面的标准能力。它们往往通过关键字(例如 await、yield 等)直接提供语法级的异步支持。然而,细心的读者可能已经注意到:CovScript 的异步基础设施全部以 API 形式提供,而非新增语法关键字。这并非技术上的局限,而是源于 CovScript 自第四代以来始终坚持的一项核心原则:
如非必要,不新增语法糖。若确有需求,优先通过 CovScript 4 的动态更新机制实现。
从 CovScript 4 起,社区采用了 “1 + N” 的发展模式,借鉴了 JavaScript + TypeScript 的生态理念:CovScript 3 作为 LTS 稳定版本,保障长期兼容与稳定性;CovScript 4 及其衍生语言(N 个领域语言) 作为快速演化的平台,支持动态更新与特性试验。这种模式既保证了专业用户对稳定环境的需求,也为前沿开发者提供了灵活的创新空间。因此,近几年 CovScript 的新增功能几乎都通过 扩展包(Extension Package) 的方式提供。例如:
- 非阻塞 I/O 功能 → 来自 network 扩展包
- Unicode 支持 → 来自 unicode 扩展包
所有扩展包只要遵循 CovScript CNI 标准,就能跟随运行时环境实现小版本更新保持 ABI 兼容、大版本更新保持 API 兼容,从而以较低的运维成本在创新与兼容性之间取得平衡。
或许有读者会问:为什么不直接基于现有的运行时环境(如 WASM、JVM)?答案很简单:自主可控与极致性能。CovScript 选择完全自研运行时环境,虽然牺牲了部分生态便利性,但换来了:
- 针对不同硬件和系统的高效定制优化
- 体积更小、启动更快的运行时
- 对国产信创环境的一流支持与兼容性
以本文提到的并发模型为例,CovScript 的自研运行时让语言层与并发调度层深度耦合,不仅能实现更高性能的协程调度,还能保证敏感代码的完全自主可控,有效规避潜在的安全与泄密风险。
3.2 CovScript 基础设施简介——函数
首先介绍一些基础概念。
像大多数编程语言一样,CovScript 的子程序被称为“函数”,主要有以下三种形式:
# 普通函数
function regular_func(...)
...
return ...
end
# 成员函数
class some_class
function member_func(...)
...
# 可以使用 this 访问函数调用时的主体对象
return this
end
end
# Lambda 闭包
var a = 10, b = {...}
# 和大多数其他语言一样,支持指定不同的 Capture 方式
var closure = [=a, b](...){
...
# 可以使用 self 来实现递归调用
return self(...)
}可以看到,这三种函数的形式是类似的,但在实际的语言层面,普通的函数被称为“function”,而成员函数和大多数 Lambda 表达式则是一种特殊的函数,称为“object_method”。object_method 在 CovScript 中被认为是包含一个隐藏参数(如 this 和 self)的函数,因此和普通函数有略微的差别,但性能上无显著区别。部分 Lambda 表达式也会被编译器优化为普通的函数。
由于 CovScript 是一种动态语言,为了避免过高的函数调用开销,CovScript 不允许对函数进行重载(成员函数在继承时可以覆写)。但所有的函数都支持可变参数、支持多变量返回:
function vargs(...args)
# 可变参列表是个普通的数组,可以进行修改
var a = args.pop_front()
# 使用结构绑定语法提取数组中的元素
var (b, c, d) = args
...
# 同时返回多个变量
return {a, b, c, d}
end
# 使用结构绑定语法提取返回的多个变量(本质上是对数组进行提取)
var (a, _, c, _) = vargs(...)需要注意的是,可变参数以及多变量返回本质上是需要在函数直接传递数组,相对普通函数会对性能有部分影响。
非可变参数函数支持声明参数的期望类型和传递方式:
function test(a, =b, c: integer, =d: string)这里,a 是默认传引用(性能最高)、b 是传值(会进行一次拷贝)、c 是传 integer 引用、d 是传 string 的拷贝。类型检查若出错会抛出异常,可以使用 try…catch 来捕获。这种语法同样适用于 Lambda 表达式。
CovScript 函数在 CovScript SDK 中可以用 cs::invoke 直接调用,SDK 会自动处理参数类型的转换。
在 CovScript 3.x 的执行模型中,包括 if 语句、函数等在内的由声明语句和 end 包围的语句集合被称为 statement block。这种抽象模型与主流编程语言的 IR 不同,有效降低了 CovScript 解释器的复杂度,也有效降低了 IR 的执行开销。
多个共享同一个 Runtime Context 的 CovScript 函数不允许多线程执行,这是因为 CovScript 也采用了引用计数 GC。和 Python 类似,CovScript 也可以通过类似 GIL 的方式实现多线程,但 GIL 不仅不是真正的“多线程”,相对协程还会带来不必要的高额开销,因此 CovScript 在语言层面上不支持多线程。
CovScript 中除了普通函数外,还有大量的 FFI 函数(主要是通过 CNI 的方式接入),比如大多数 I/O 函数。这类函数被称为原生函数(Native Function)。原生 I/O 函数大多数是线程安全的,如何异步执行这些函数后面我们会提到。
3.3 CovScript 基础设施简介——协程
CovScript 协程被称为纤程(Fiber),这样叫主要是与 Go 协程区分(Coroutine),因为 CovScript 纤程是不能在多个 CPU 核心上并行执行的,单个 CovScript Runtime Context 中的纤程只能共享一个 CPU 核心的时间片。
CovScript 纤程只能从 CovScript 函数的基础上创建,无法在原生函数的基础上创建,这是因为 CovScript 纤程依赖 CovScript Runtime 进行调度和资源管理。创建纤程的方式非常简单:
var co = fiber.create(func, ...)只能在创建时传递需要的参数给纤程。纤程在执行时和普通的函数无异,可以读取全局命名空间中的变量。除了在创建时传递参数,还可以在 Lambda 函数的基础上创建纤程,通过 Capture 的方式传递参数到纤程内部。
纤程创建后不会自动执行,需要手动调用 resume 来唤醒。同理,若纤程不通过 fiber.yield() 手动挂起,时间片也会一直被纤程占用,直到执行完毕。纤程对象有以下方法:
# 唤醒纤程。若纤程在唤醒期间抛出异常,会将异常转发至此处
co.resume()
# 判断是否运行,返回布尔量
co.is_running()
# 判断是否挂起,返回布尔量
co.is_suspended()
# 判断是否结束,返回布尔量
co.is_finished()
# 获取纤程的返回值,在纤程未正常结束的情况下会抛出异常
co.return_value()纤程有下列特性:
- 纤程有独立的栈空间,栈空间中的变量会随着纤程挂起隐藏和唤醒恢复,挂起和恢复不会影响其生命周期
- 纤程可以递归或嵌套调用其他函数或纤程,递归或嵌套深度受运行时环境的总数限制
- 纤程不可重入,即结束的纤程不能再次唤醒(resume)。若需要重入纤程,需要重新调用 fiber.create 创建
- 纤程的总数仅受操作系统文件描述符/句柄总数限制和内存限制,CovScript 运行时环境未进行限制
CovScript SDK 中提供了类似的 API,可以在 C++ 环境中调用:
#include <covscript/cni.hpp>
// 纤程状态
cs::fiber_state::ready
cs::fiber_state::running
cs::fiber_state::suspended
cs::fiber_state::finished
// 纤程对象:cs::fiber_t
// 可能的实现:std::shared_ptr<cs::fiber_type>
// 创建纤程,需传入 Context 对象(可通过 cs::bootstrap 创建)
cs::fiber_t co = cs::fiber::create(cs::context_t, std::function<var()>);
// 唤醒纤程
cs::fiber::resume(co);
// 挂起纤程
cs::fiber::yield();
// 获取纤程的状态
cs::fiber_state state = co->get_state();
// 获取纤程的返回值
cs::var value = co->return_value();对于绝大多数开发者来说,最常用的是 cs::fiber::yield(),可以在阻塞 API 运行期间手动挂起纤程。要判断当前是否为纤程环境:
// 若 fiber_stack 不为空,则说明当前在纤程环境
// 如果你不清楚这是什么,请不要直接修改 current_process 或 fiber_stack 中的内容
cs::current_process->fiber_stack.empty()事实上,runtime.await 的底层实现可以近似认为是基于这些 API 的。下一节中我们会详细进行介绍。
3.4 CovScript 基础设施简介——异步
CovScript 提供了丰富的异步 API,首先介绍 Runtime 内嵌的方法:
runtime.await(func, args...)该函数会阻塞当前控制流,直到函数执行完毕。要求函数必须是线程安全的原生函数(见 3.2)。下面列出一些常见的与 await 搭配使用的 I/O 函数:
# 输出函数
ostream.print(str)
ostream.println(str)
ostream.write(str)
# 输入函数
istream.input()
istream.getline()
istream.read(n)其中,ostream 可以是 system.out、system.err、system.log、输出文件流和 char_buff 获取的 ostream 对象;istream 可以是 system.in、输入文件流和 char_buff 获取的 istream 对象。需要注意的是,char_buff 不能在 await 的同时进行其他 I/O 操作。
runtime.await 可以安全的在任何地方使用:在普通的控制流中,该函数与普通的函数调用开销类似;在纤程的控制流中,该函数会自动让出时间片(挂起)。一个典型的用法如下:
var c = fiber.create([]()->runtime.await(system.in.getline))
loop
c.resume()
# 这里可以随意做些其他事情
until c.is_finished()
system.out.println("Input = " + c.return_value())这个示例程序将 Lambda 表达式转换为了一个纤程,并通过 runtime.await 异步等待用户的输入。由于 await 函数会返回所等待函数的返回值,而 Lambda 表达式又会进一步将该值返回给纤程调度器,最终可以通过 return_value 方法获取。
除此之外,network 包进一步提供了丰富的非阻塞 I/O 功能。要安装 network 包,只需要使用 CSPKG 包管理器:
cspkg install network --yes如果你的网络连接不好、我们的服务器不稳定(难说,要怪就怪阿里云)或想使用最新的包(我们服务器同步的频率大概一周一次),也可以到 CovScript OSC GitHub 主页 上手动下载自己对应平台的 CSPKG 离线 Repository,一般是一个 7z 压缩包。解压后得到 cspkg-repo 文件夹,将该文件夹的绝对路径填写到 CSPKG 配置文件中(一般在~/.cspkg/config.json):
{
"arch" : 参考 cs -v 的输出,乱设置会导致错误,
"home" : 存储 CovScript 包的位置,
"source" : "file://到cspkg-repo的绝对路径",
"timeout_ms" : "3000"
}偶尔在大版本更新后,会破坏本地的依赖。这个时候直接删除~/.covscript目录(或者自己设置的目录)后重新安装即可。
也可以直接通过 CSPKG 命令设置源目录:
cspkg config source --app file://到cspkg-repo的绝对路径除了 network 包,CovScript 社区还同时维护了 curl 和 netutils 和 包,下面我们将一同介绍。
如同包名,network 包提供了与计算机网络通讯相关的基础设施。该包的底层基于大名鼎鼎的 ASIO 高性能网络库,为 CovScript 提供了强壮的底层网络通讯能力。而 curl 则直接是 curl 的 CovScript 包装,提供了强大的 HTTP 客户端功能。在这两者的基础上,netutils 则是一个使用 CovScript 4 开发的工具集,分别提供了基于 network 包装的高性能异步 HTTP 服务器和基于 curl 包装的 HTTP 客户端。我们在这里不会详细介绍这三个包的功能,感兴趣的朋友可以去查阅 CovScript Manual(截止2025年10月,这部分内容暂时缺失)。
network 包的功能主要在三个命名空间中提供:tcp、udp 和 async。一般在引入 network 包时,我们推荐不要省事使用 network.*,而是明确地引入三个命名空间:
import network.tcp, network.udp, network.asyncCovScript 的 tcp 和 udp 模块主要提供了底层的 网络套接字(Socket) 功能。在默认情况下,这些 API 均为阻塞式实现,逻辑清晰、易于理解,适合简单的网络交互场景。
例如,创建 TCP 连接的基本用法如下:
# 新建套接字对象
var sock = new tcp.socket
# 若作为服务器,绑定一个本地端口,如8888
var ac = tcp.acceptor(tcp.endpoint_v4(8888))
# 接受一个连接(阻塞,错误时抛出异常)
sock.accept(ac)
# 阻塞当前纤程等待(错误时抛出异常)
runtime.await(sock.accept, ac)可以看到,API 设计是非常直观的,与底层系统调用一一对应。但它的一个明显缺点在于:每次调用 await 时,底层都需要启动一个线程去异步等待事件完成。这在高并发场景下会带来额外的线程调度开销。为了进一步提升性能,network 扩展包提供了原生的 异步 I/O API,所有操作均基于事件循环(Event Loop),无需额外线程:
# 提交任何异步任务之前需在当前作用域新建一个 work_guard
# 当 work_guard 不存在时,底层事件循环将暂停以节约开销
var async_guard = new async.work_guard
# 接受一个连接(非阻塞)
var state = async.accept(sock, ac)
# 手动轮询
loop
# 执行所有就绪事件,不阻塞等待新事件
# 若事件执行完毕返回 false
if !async.poll()
break
end
# 仅执行一个事件,不阻塞等待新事件
# 若事件执行完毕返回 false
if !async.poll_once()
break
end
# 这里可以随意做些其他事情
until state.has_done()
# 检查任务状态
var error = state.get_error()
if error == null
system.out.println("Accept Succeeded")
else
system.out.println("Accept Error: " +
state.get_error())
end这里涉及的所有 API 均属于 Asynchronous Native 层,调用几乎没有额外的系统开销。CovScript 异步框架中有两种事件调度函数:
- async.poll():执行所有已就绪事件,延迟较高,但 CPU 占用低,适合吞吐优先的场景;
- async.poll_once():仅执行一个就绪事件,延迟更低,但可能导致忙等,适合延迟敏感的场景。
在事件执行后,可以通过 state.has_done() 判断任务是否完成。
此外,network 模块还提供了更高级的封装函数:
# 阻塞当前纤程等待,错误时返回 false
if !state.wait()
# 处理错误
system.out.println("Accept Error: " +
state.get_error())
end
# 阻塞当前纤程等待特定时长(毫秒),超时或错误时返回 false
if !state.wait_for(1000)
# 处理错误
if state.has_done()
system.out.println("Accept Error: " +
state.get_error())
else
system.out.println("Accept Error: Timeout")
end
endwait 和 wait_for 是对手动轮询的封装,它们在底层使用了 C++ 实现的自旋与协程切换逻辑,因此在性能上比纯 CovScript 层轮询更加高效。它们的行为类似于 await:
- 在普通控制流中,会阻塞当前线程直到任务完成、超时或出错;
- 在纤程控制流中,则会自动挂起(yield),让出时间片。
其他的 API 也可以像 accept 一样使用,下面列出常用的阻塞 API 和对应的非阻塞 API:
# 阻塞 API
# 连接到远程服务器
sock.connect(ep)
# 从远程读取定量数据
var data = sock.read(n)
# 向远程发送定量数据
sock.write(data)# 非阻塞 API
# 连接到远程服务器
async.connect(sock, ep)
# 从远程读取定量数据
async.read(sock, n)
# 向远程发送定量数据
async.write(data)除此之外,还有一些常用的方法:
# 通信端点
# 可以用 127.0.0.1 (v4) 或 ::1 (v6) 指定本地回环
var ep = tcp.endpoint("IP地址", 端口)
# v4 本机地址 0.0.0.0
var ep_v4 = tcp.endpoint_v4(端口)
# v6 本机地址 ::
var ep_v6 = tcp.endpoint_v6(端口)
# 使用 DNS 解析通信端点,服务一般是 http/https/ftp 等
# 返回可用端点数组
var eps = tcp.resolve("主机名", "服务")
# 套接字
# 判断连接是否建立
sock.is_open()
# 返回缓存中有多少立刻可用的字节
sock.available()
# 主动关闭连接
# 使用 sock = null 效果相同
sock.close()
# 异步事件
# 获取本次异步事件执行的结果
var str = state.get_result()
# 读取一部分缓冲区
var buff = state.get_buffer(max_bytes)
# 返回缓存中有多少立刻可用的字节
state.available()
# 判断是否遇到了 EOF
state.eof()
# 返回异步事件的错误,无错误时返回 null
state.get_error()在网络通信中,很多协议(如 HTTP、SMTP 等)并不会提前声明消息长度,而是通过特殊分隔符(如 \r\n 或空行)来标记数据结束。为了应对这种场景,CovScript 提供了一个非常好用的异步接口:async.read_until。这个 API 可以异步地读取数据直到匹配到指定正则表达式,是构建协议解析器(例如 HTTP 服务器)的利器。
下面的示例展示了一个经典的 read_until 循环读取逻辑:
import netutils
var header = new array
var state = new async.state
var pattern = "\r\n"
loop
# 复用 state 以传入未消耗完的字节
async.read_until(sock, state, pattern)
if !state.wait()
# 处理错误
system.out.println("Read Error: " +
state.get_error())
end
# 仅读取本次异步事件执行的结果
var line = state.get_result().trim()
# 遇到 \r\n\r\n 时结束(HTTP 请求头结束)
if line.empty()
break
else
header.push_back(line)
end
end
# 构建 HTTP 请求头
var session = new netutils.http_session{null, header}
if session.method == "POST"
# 获取剩余缓冲区中的字节
var post_body =
state.get_buffer(session.content_length)
var remain_length =
session.content_length - post_body.size
# 若未读完,则阻塞读取剩余字节
if remain_length > 0
post_body += sock.read(remain_length)
end
else
# 获取剩余缓冲区中的字节(即首行后的请求体内容)
var remain = state.get_buffer(state.available())
end与 async.read 不同,async.read_until 并不会读取固定长度的数据。其工作流程如下:
- 每次从套接字中读取一部分数据到内部缓冲区;
- 在缓冲区中对数据进行正则匹配;
- 若匹配成功,则触发完成事件,否则继续异步读取。
这种机制虽然非常灵活,但也意味着它可能会“多读”一些数据(即超出匹配点之后还会留有多余字节)。因此,为了不丢失这些数据,循环调用时必须复用上一次使用的 state 对象。
在上面的例子里,我们利用了 netutils 提供的 API 对 HTTP 请求头进行了解析,并当请求为 POST 时读取剩余的内容。如果没有类似 read_until 的 API,构建一个 HTTP 服务器的逻辑将变得十分复杂。
总的来说,async.read_until 的优势在于,支持基于正则的非定长读取,特别适合构建基于文本协议的高并发网络服务(如 HTTP、FTP、SMTP 等)。换句话说,它让异步编程不再受限于“定长缓冲区”的思维模式,使得网络通讯逻辑更贴近协议语义本身。
3.4 高性能异步并发 HTTP 服务器:Netutils
并不是每个开发者都希望从零开始编写一个完整的 HTTP 服务器。更何况,在现代开发中,“重复造轮子”往往并非明智之举。因此,CovScript 在 netutils 包中基于前面介绍的异步基础设施,提供了一个单线程高并发 HTTP 服务器的实现,只需几行代码即可启动:
import netutils
var server = new netutils.http_server
server.set_wwwroot("./wwwroot").listen(8080)
server.bind_func("/test", [](server, session, data){
session.send_response(
netutils.state_codes.code_200,
"Hello, world!",
"text/plain")
})
server.run()没错,这样就够了。只需在 wwwroot 目录下放置网页文件(例如 index.html),运行脚本后,你就能在本机的 8080 端口访问到一个简洁高效的 HTTP 服务。
netutils 的 HTTP 服务器完全基于 CovScript 的 异步网络层(network 包) 实现,通过单线程的事件循环机制支撑起近万级并发连接。这听起来像是天方夜谭,但事实上,这个性能已经接近Nginx 等高性能 HTTP 服务器或 Go / Rust 等语言实现的现代并发 Web 服务。之所以能做到这一点,正是因为 CovScript 的异步架构将 I/O 等待与逻辑调度完全解耦,CPU 几乎不再因网络阻塞而空转。
甚至,如果你希望完全掌控执行节奏,CovScript 也提供了选择:
loop
server.poll()
# 这里可以随意做些其他事情
end这样的写法意味着你可以在服务器轮询时插入任意逻辑,实现更灵活的系统组合。当然,这样做也要谨慎:事件循环的响应速度直接决定 HTTP 服务的延迟与吞吐量,因此不应在循环内执行复杂计算或阻塞操作。但这段代码也向我们揭示了一个事实:随着现代 CPU 晶体管数量不断增加、IPC 机制不断改进,真正能吃满单核算力的任务已经越来越少。单核往往代表了最小延迟、最简单的并发模型。只要能高效利用单核的计算能力,即便不依赖多线程,也足以支撑相当规模的高并发场景。
CovScript 的设计理念正是如此:用轻量级协程和非阻塞式 I/O 最大化单核性能,再通过多进程扩展至更高层次的并发能力。这是一种从底层到工程的优雅平衡——既简洁又强大,让“单线程”也能拥有“并发”的力量。
当然,单线程架构并非万能。当服务逻辑中包含大量非 I/O 密集型任务(例如数据库访问或文件解析)时,单线程模型依然可能成为瓶颈。为此,我们正在开发基于多进程模型的 netutils HTTP 服务器版本,它将支持多核并发与独立进程隔离,进一步提升在复杂场景下的吞吐能力。完成后,我们会在本文中更新使用方法与性能测试结果,敬请期待。
四、在大模型和云原生时代,CovScript 如何发挥其优势?
如今的技术圈,仿佛一夜之间,“Cloud Native”、“LLM Native”成了新的通关暗号。无论是新语言、框架还是平台,都纷纷贴上这些标签,宣称自己是“为云而生”、“为智能体而造”。而 CovScript,一个诞生于 2017 年初、设计理念诞生在“云原生”尚未流行的年代的语言,自然很难在这种宣传口径中占到便宜。
但这并不代表它落后。
事实上,到 2025 年这个时间点,我并不认为有任何一门“功能正常”的编程语言无法完成微服务的搭建,或者驱动一个大模型 Agent 的运行。差别只在于:你要写多少行代码、能否保持足够清晰的结构,以及:是否真的理解了“异步”“并发”“无阻塞”的本质。
当然,以上不过是些牢骚。既然大家都在聊“云原生”和“大模型”,那我们不妨也入乡随俗,看看 CovScript 是如何在今天的潮流语境下,用自己的方式实现最“潮”的需求。
4.1 数据库的连接与读写
未完待续
4.2 进程的生成与通讯
未完待续
4.3 数据的编码与加密
未完待续


